
About
-
I am a research scientist at imagia. I focus on developing machine learning methods applicable to healthcare. My research interests include representation learning, meta-learning and uncertainty. From 2016 to 2018 I was a member of Montreal Institute for Learning Algorithms (MILA) as a postdoctoral fellow under the supervision of Aaron Courville. Prior to that, I obtained my PhD at University of Sherbrooke under the supervision of Hugo Larochelle and Pierre-Marc Jodoin. The main focus of my PhD was developing deep learning models applied to medical images for brain tumor segmentation.
-
Among winners of the Brain Tumor Segmentation Challenge (BRATS) 2015.

Selected Publications
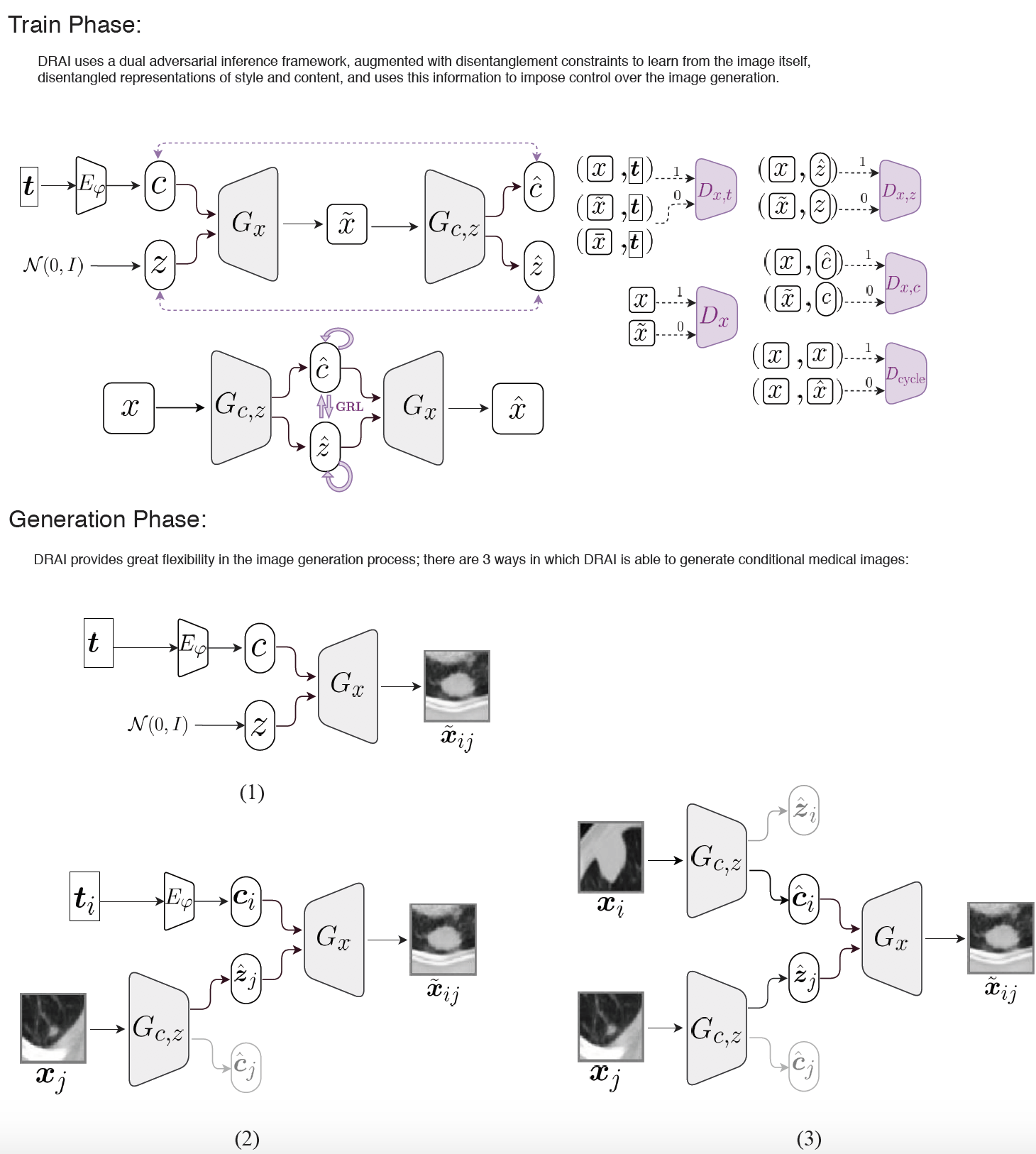
Conditional generation of medical images via disentangled adversarial inference
Journal of Medical Image Analysis 2021
Synthetic medical image generation has a huge potential for improving healthcare through many applications, from data augmentation for training machine learning systems to preserving patient privacy. Conditional Adversarial Generative Networks (cGANs) use a conditioning factor to generate images and have shown great success in recent years. Intuitively, the information in an image can be divided into two parts: 1) content which is presented through the conditioning vector and 2) style which is the undiscovered information missing from the conditioning vector. Current practices in using cGANs for medical image generation, only use a single variable for image generation (i.e., content) and therefore, do not provide much flexibility nor control over the generated image.
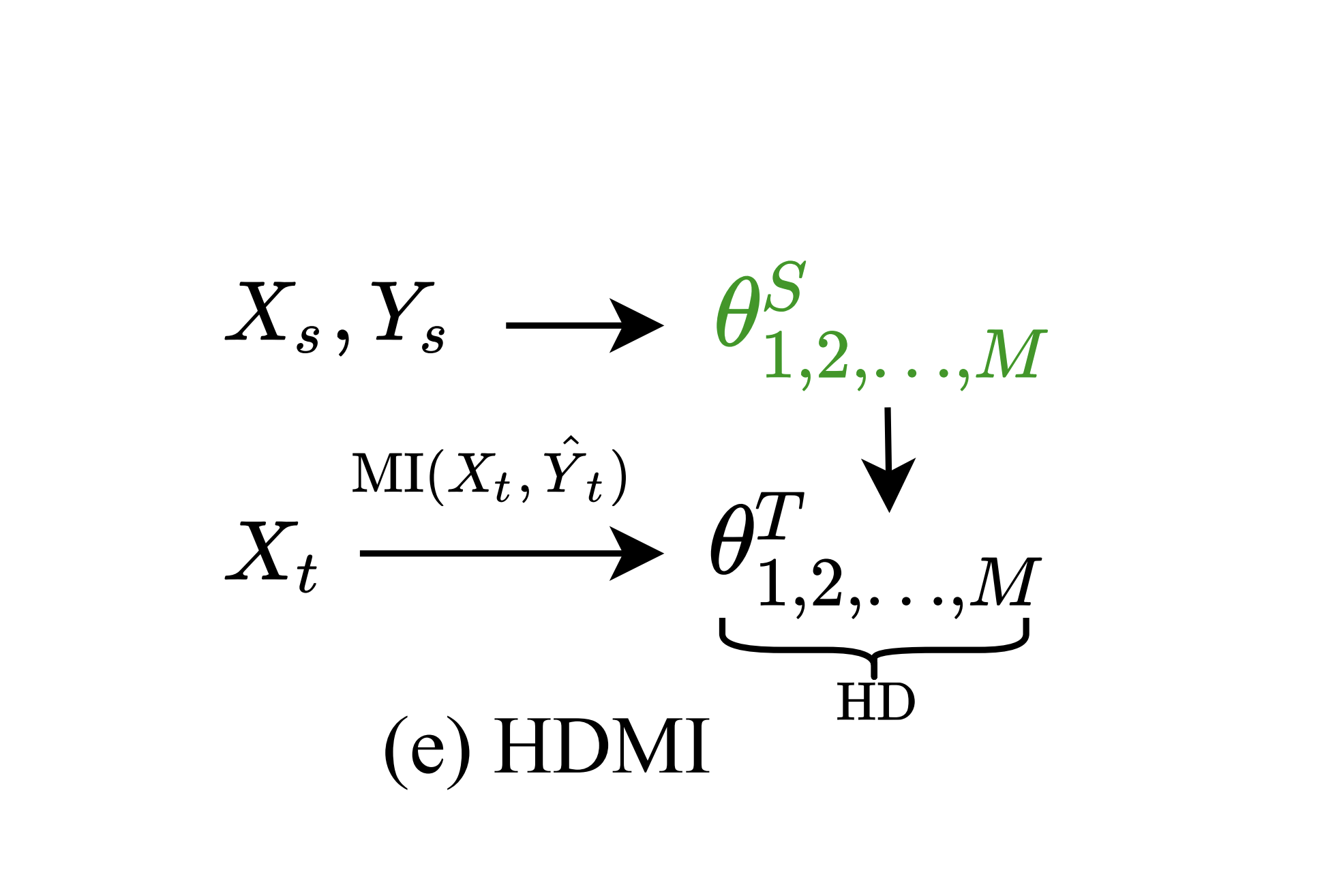
Hypothesis disparity regularized mutual information maximization
AAAI 2020
We propose a hypothesis disparity regularized mutual information maximization~(HDMI) approach to tackle unsupervised hypothesis transfer -- as an effort towards unifying hypothesis transfer learning (HTL) and unsupervised domain adaptation (UDA) -- where the knowledge from a source domain is transferred solely through hypotheses and adapted to the target domain in an unsupervised manner. In contrast to the prevalent HTL and UDA approaches that typically use a single hypothesis, HDMI employs multiple hypotheses to leverage the underlying distributions of the source and target hypotheses. To better utilize the crucial relationship among different hypotheses -- as opposed to unconstrained optimization of each hypothesis independently -- while adapting to the unlabeled target domain through mutual information maximization, HDMI incorporates a hypothesis disparity regularization that coordinates the target hypotheses jointly learn better target representations while preserving more transferable source knowledge with better-calibrated prediction uncertainty. HDMI achieves state-of-the-art adaptation performance on benchmark datasets for UDA in the context of HTL, without the need to access the source data during the adaptation.
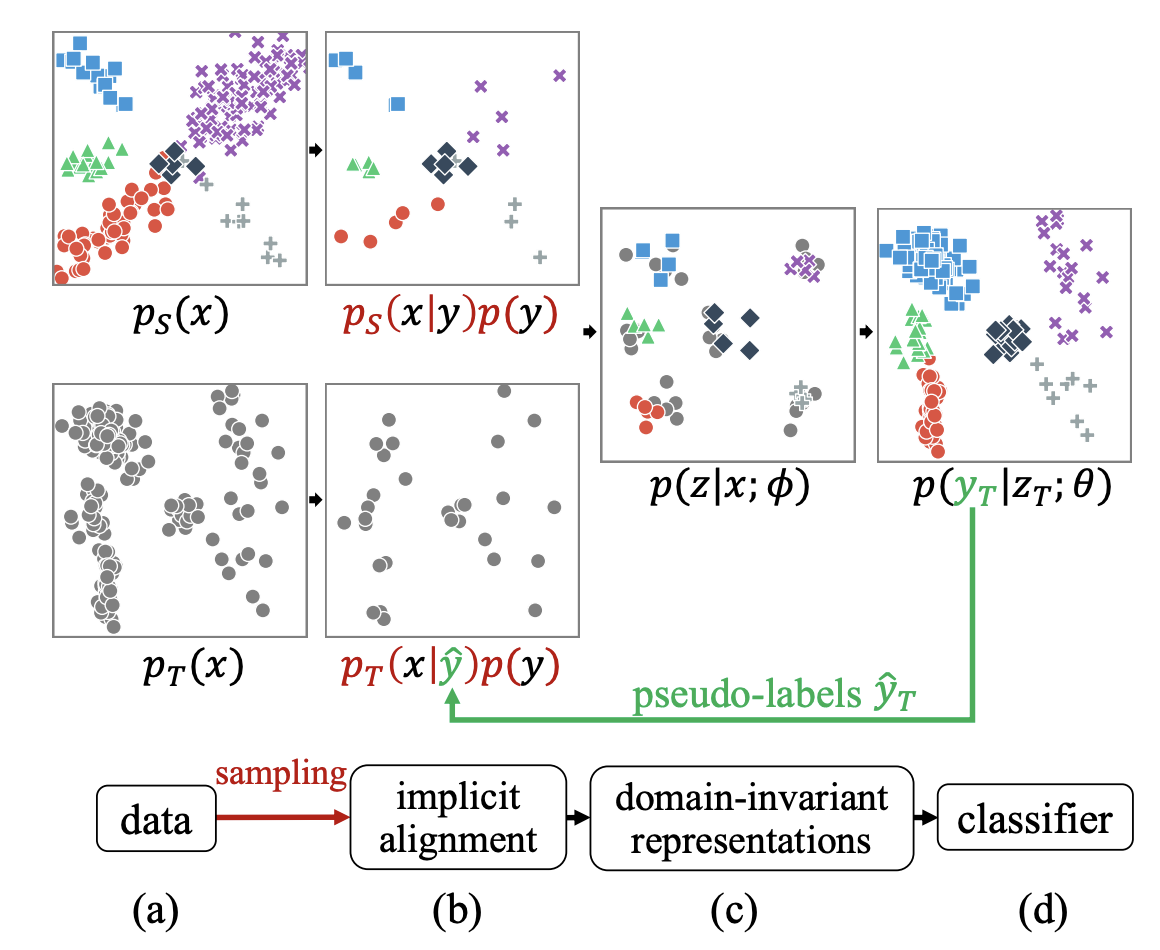
Implicit class-conditioned domain alignment for unsupervised domain adaptation
ICML 2020
We present an approach for unsupervised domain adaptation {—} with a strong focus on practical considerations of within-domain class imbalance and between-domain class distribution shift {—} from a class-conditioned domain alignment perspective. Current methods for class-conditioned domain alignment aim to explicitly minimize a loss function based on pseudo-label estimations of the target domain. However, these methods suffer from pseudo-label bias in the form of error accumulation. We propose a method that removes the need for explicit optimization of model parameters from pseudo-labels. Instead, we present a sampling-based implicit alignment approach, where the sample selection is implicitly guided by the pseudo-labels. Theoretical analysis reveals the existence of a domain-discriminator shortcut in misaligned classes, which is addressed by the proposed approach to facilitate domain-adversarial learning. Empirical results and ablation studies confirm the effectiveness of the proposed approach, especially in the presence of within-domain class imbalance and between-domain class distribution shift..
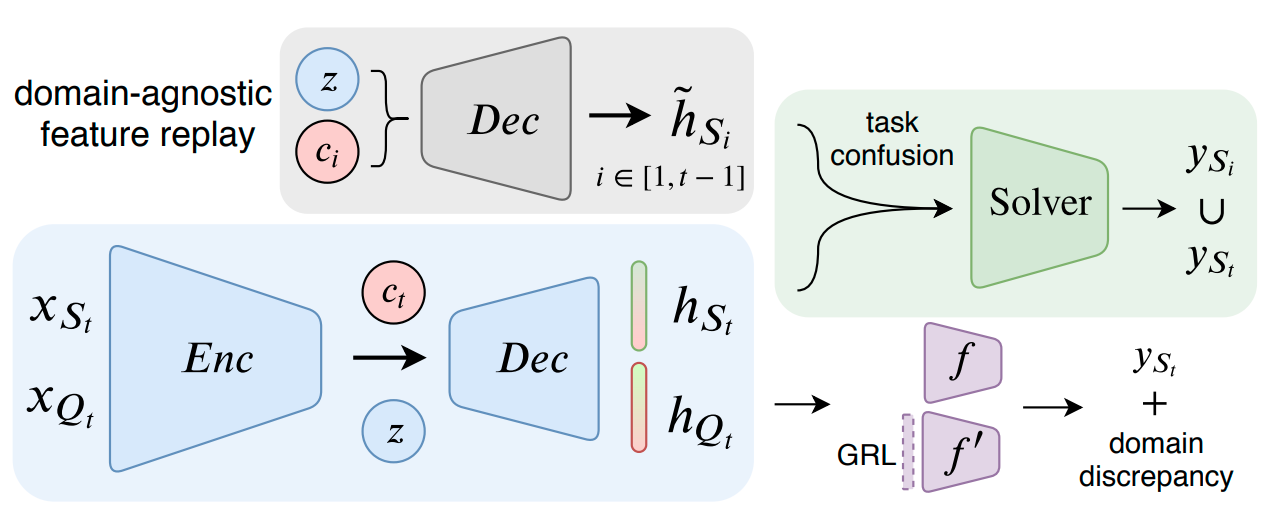
Continuous Domain Adaptation with Variational Domain-Agnostic Feature Replay
Arxiv
Learning in non-stationary environments is one of the biggest challenges in machine learning. Non-stationarity can be caused by either task drift, ie, the drift in the conditional distribution of labels given the input data, or the domain drift, ie, the drift in the marginal distribution of the input data. This paper aims to tackle this challenge in the context of continuous domain adaptation, where the model is required to learn new tasks adapted to new domains in a non-stationary environment while maintaining previously learned knowledge. To deal with both drifts, we propose variational domain-agnostic feature replay, an approach that is composed of three components: an inference module that filters the input data into domain-agnostic representations, a generative module that facilitates knowledge transfer, and a solver module that applies the filtered and transferable knowledge to solve the queries. We address the two fundamental scenarios in continuous domain adaptation, demonstrating the effectiveness of our proposed approach for practical usage.
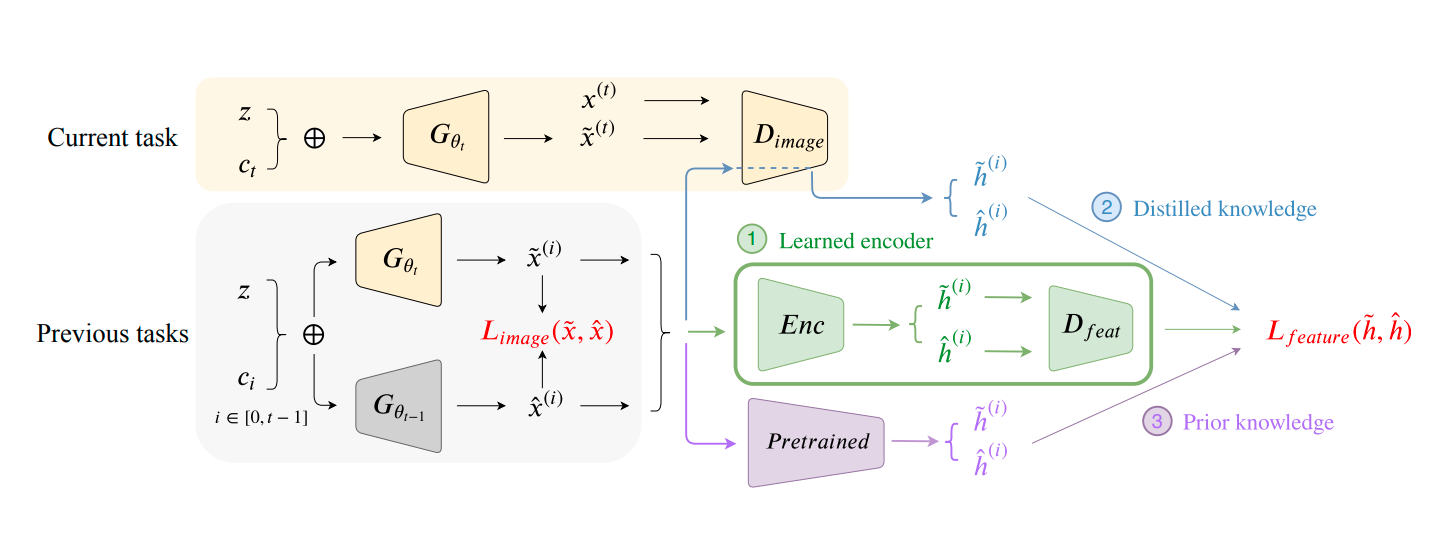
FoCL: Feature-Oriented Continual Learning for Generative Models
Arxiv
In this paper, we propose a general framework in continual learning for generative models: Feature-oriented Continual Learning (FoCL). Unlike previous works that aim to solve the catastrophic forgetting problem by introducing regularization in the parameter space or image space, FoCL imposes regularization in the feature space. We show in our experiments that FoCL has faster adaptation to distributional changes in sequentially arriving tasks, and achieves the state-of-the-art performance for generative models in task incremental learning. We discuss choices of combined regularization spaces towards different use case scenarios for boosted performance, eg, tasks that have high variability in the background. Finally, we introduce a forgetfulness measure that fairly evaluates the degree to which a model suffers from forgetting. Interestingly, the analysis of our proposed forgetfulness score also implies that FoCL tends to have a mitigated forgetting for future tasks.
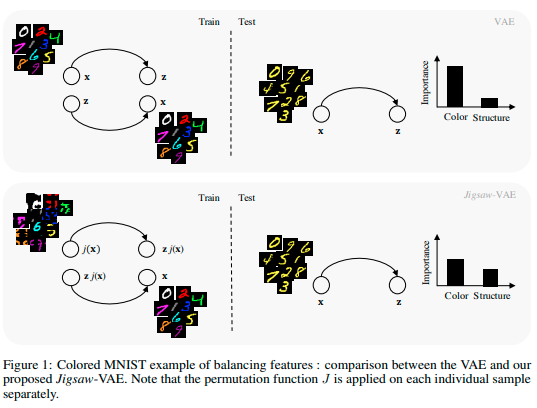
Jigsaw-VAE: Towards Balancing Features in Variational Autoencoders
Arxiv
The latent variables learned by VAEs have seen considerable interest as an unsupervised way of extracting features, which can then be used for downstream tasks. There is a growing interest in the question of whether features learned on one environment will generalize across different environments. We demonstrate here that VAE latent variables often focus on some factors of variation at the expense of others-in this case we refer to the features as``imbalanced''. Feature imbalance leads to poor generalization when the latent variables are used in an environment where the presence of features changes. Similarly, latent variables trained with imbalanced features induce the VAE to generate less diverse (ie biased towards dominant features) samples. To address this, we propose a regularization scheme for VAEs, which we show substantially addresses the feature imbalance problem. We also introduce a simple metric to measure the balance of features in generated images.

Dual Adversarial Inference for Text-to-Image Synthesis
ICCV'19
Synthesizing images from a given text description involves engaging two types of information: the content information which includes information explicitly described in the text (e.g., color, composition, etc.) and the style information which is usually not well described in the text (e.g., location, quantity, size, etc.). However, in previous works, it is typically treated as a process of generating images only from the content, i.e., without considering learning meaningful style representations. In this paper, we aim to learn two variables that are disentangled in the latent space, representing content and style respectively. We achieve this by augmenting current text-to-image synthesis frameworks with a dual adversarial inference mechanism. We show that our model learns, in an unsupervised manner, style representations corresponding to certain meaningful information present in the image that are not well described in the text.
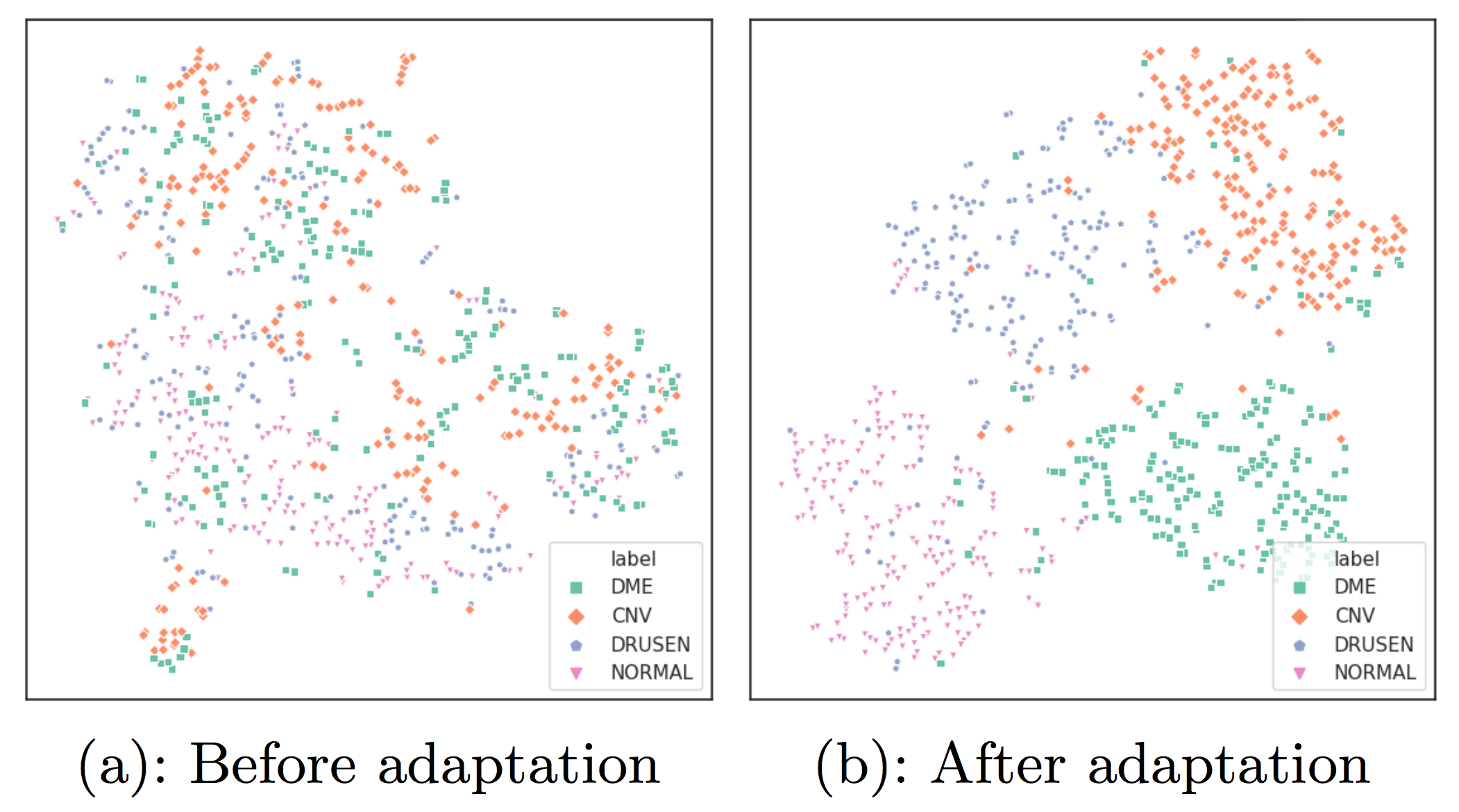
Task Adaptive Metric Space for Medium-Shot Medical Image Classification
MICCAI'19
In the medical domain, one challenge of deep learning is to build sample-efficient models from a small number of labeled data. In recent years, meta-learning has become an important approach to few-shot image classification. However, current research on meta-learning focuses on learning from a few examples; we propose to extend few-shot learning to medium-shot to evaluate medical classification tasks in a more realistic setup. We build a baseline evaluation procedure by analyzing two representative meta-learning methods through the lens of bias-variance tradeoff, and propose to fuse the two techniques for better bias-variance equilibrium. The proposed method, Task Adaptive Metric Space (TAMS), fine-tunes parameters of a metric space to represent medical data in a more semantically meaningful way. Our empirical studies suggest that TAMS outperforms other baselines. Visualizations on the metric space show TAMS leads to better-separated clusters. Our baselines and evaluation procedure of the proposed TAMS opens the door to more research on medium-shot medical image classification.
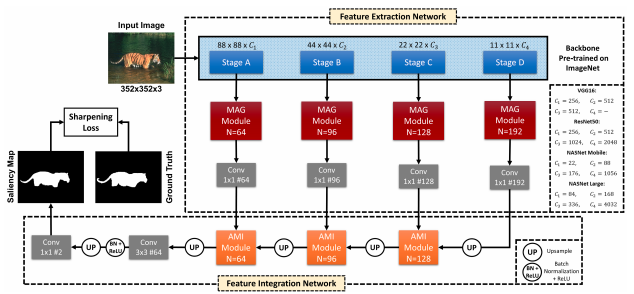
DFNet: Discriminative feature extraction and integration network for salient object detection
Engineering Applications of Artificial Intelligence
Despite the powerful feature extraction capability of Convolutional Neural Networks, there are still some challenges in saliency detection. In this paper, we focus on two aspects of challenges: i) Since salient objects appear in various sizes, using single-scale convolution would not capture the right size. Moreover, using multi-scale convolutions without considering their importance may confuse the model. ii) Employing multi-level features helps the model use both local and global context. However, treating all features equally results in information redundancy. Therefore, there needs to be a mechanism to intelligently select which features in different levels are useful. To address the first challenge, we propose a Multi-scale Attention Guided Module. This module not only extracts multi-scale features effectively but also gives more attention to more discriminative feature maps corresponding to the scale of the salient object. To address the second challenge, we propose an Attention-based Multi-level Integrator Module to give the model the ability to assign different weights to multi-level feature maps. Furthermore, our Sharpening Loss function guides our network to output saliency maps with higher certainty and less blurry salient objects, and it has far better performance than the Cross-entropy loss. For the first time, we adopt four different backbones to show the generalization of our method. Experiments on five challenging datasets prove that our method achieves the state-of-the-art performance. Our approach is fast as well and can run at a real-time speed.
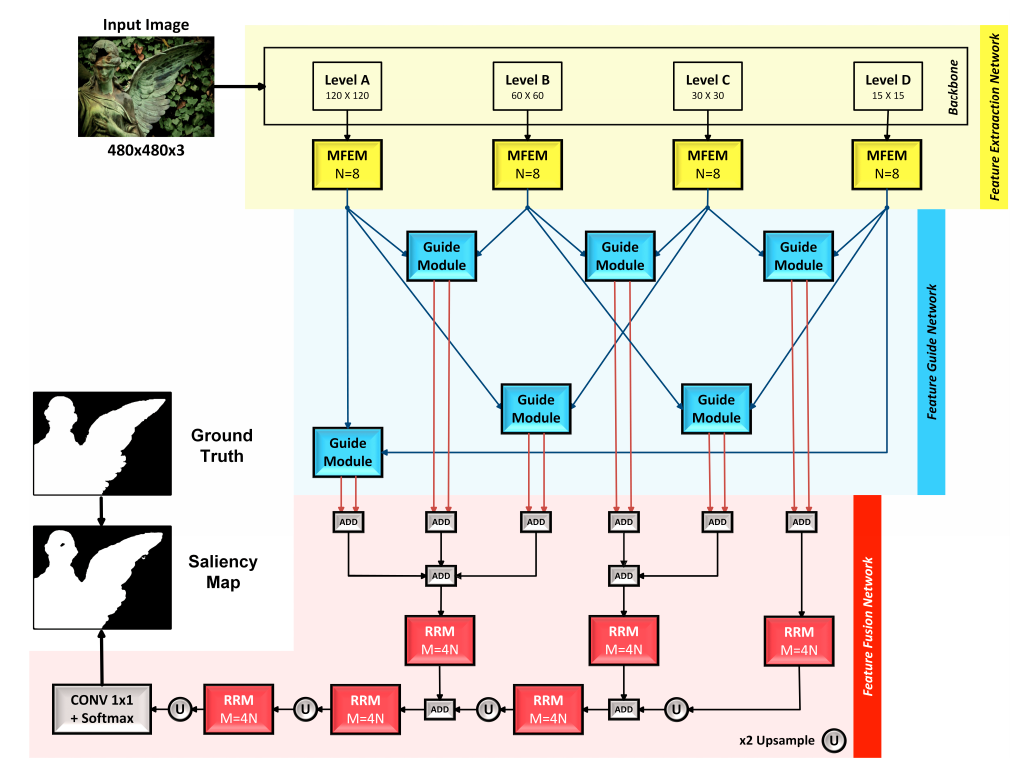
CAGNet: Content-Aware Guidance for Salient Object Detection
Pattern Recognition
Beneficial from Fully Convolutional Neural Networks (FCNs), saliency detection methods have achieved promising results. However, it is still challenging to learn effective features for detecting salient objects in complicated scenarios, in which i) non-salient regions may have “salient-like” appearance; ii) the salient objects may have different-looking regions. To handle these complex scenarios, we propose a Feature Guide Network which exploits the nature of low-level and high-level features to i) make foreground and background regions more distinct and suppress the non-salient regions which have “salient-like” appearance; ii) assign foreground label to different-looking salient regions. Furthermore, we utilize a Multi-scale Feature Extraction Module (MFEM) for each level of abstraction to obtain multi-scale contextual information. Finally, we design a loss function which outperforms the widely used Cross-entropy loss. By adopting four different pre-trained models as the backbone, we prove that our method is very general with respect to the choice of the backbone model. Experiments on six challenging datasets demonstrate that our method achieves the state-of-the-art performance in terms of different evaluation metrics. Additionally, our approach contains fewer parameters than the existing ones, does not need any post-processing, and runs fast at a real-time speed of 28 FPS when processing a 480 × 480 image.
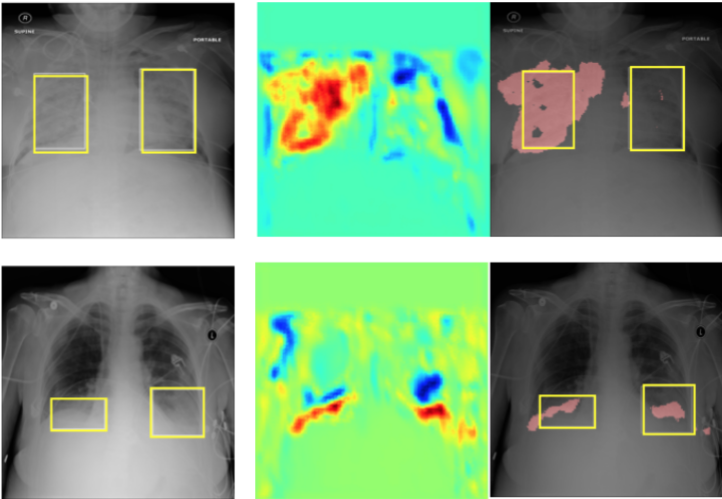
InfoMask: Masked Variational Latent Representation to Localize Chest Disease
MICCAI'19
We present a model for weaklocalization through maximizig a mutual information objectinve.
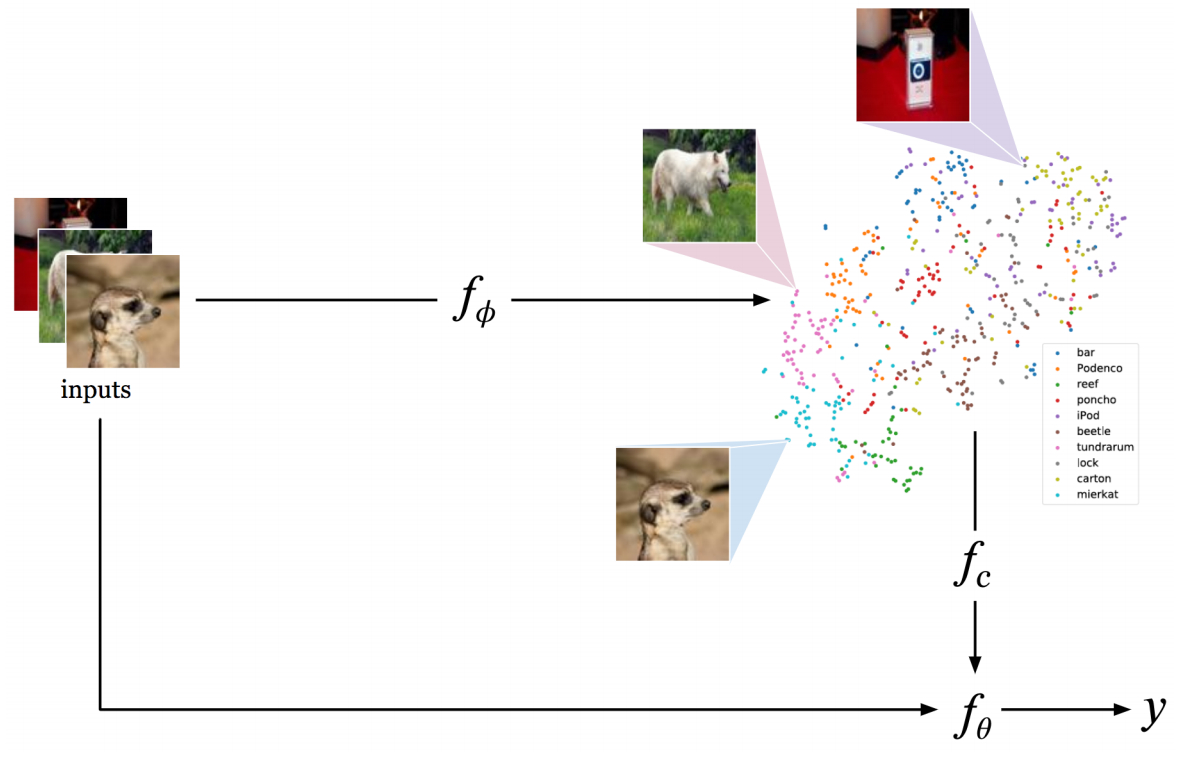
Learning to learn with conditional class dependencies
ICLR 2019
CAML is a kind of MAML
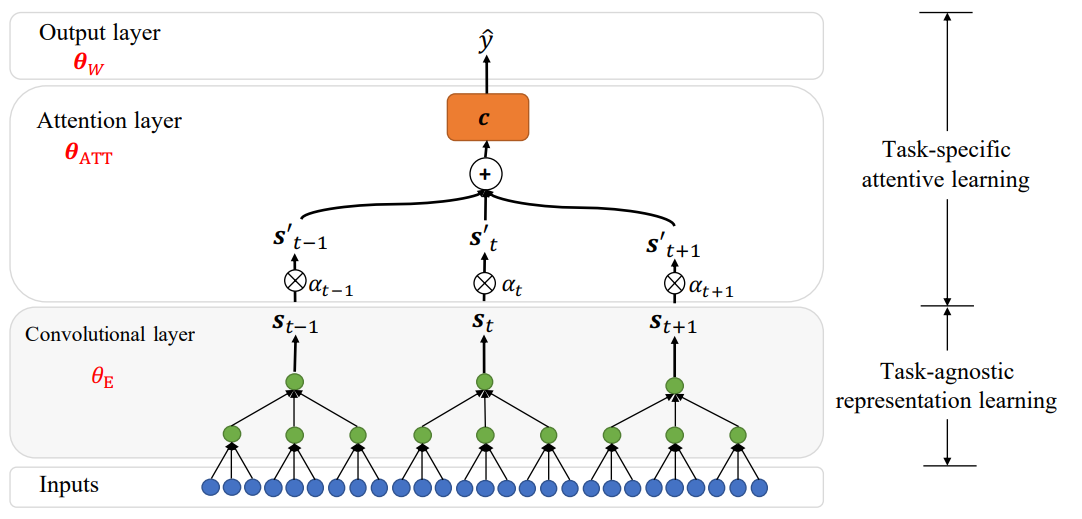
Attentive Task-Agnostic Meta-Learning for Few-Shot Text Classification
Meta-learning workshop,NeurIPS 2018
Meta learning for text classification.

On the Importance of Attention in Meta-Learning for Few-Shot Text Classification
arXiv (oral)
Attentive metalearner for text classifcation.
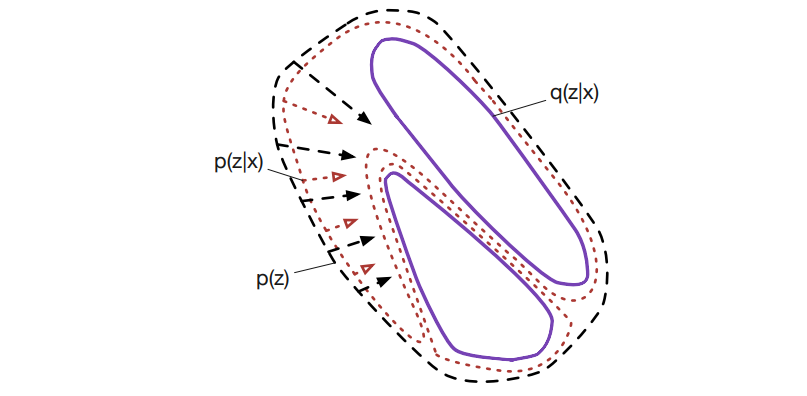
Learnable explicit density for continuous latent space and variational inference
arXiv
In this paper, we study two aspects of the variational autoencoder (VAE): the prior distribution over the latent variables and its corresponding posterior. First, we decompose the learning of VAEs into layerwise density estimation, and argue that having a flexible prior is beneficial to both sample generation and inference. Second, we analyze the family of inverse autoregressive flows (inverse AF) and show that with further improvement, inverse AF could be used as universal approximation to any complicated posterior. Our analysis results in a unified approach to parameterizing a VAE, without the need to restrict ourselves to use factorial Gaussians in the latent real space.
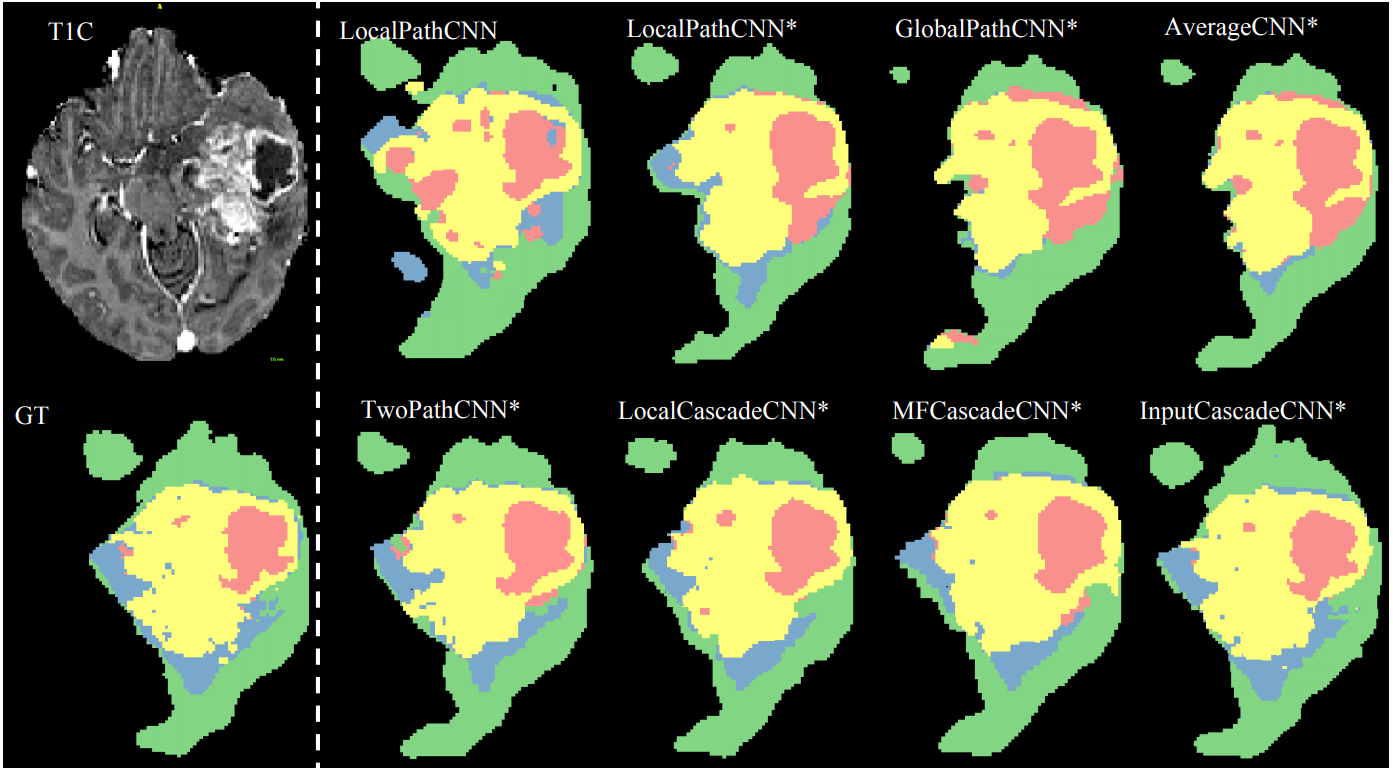
Brain tumor segmentation with deep neural networks
Medical Image Analysis
In this paper, we present a fully automatic brain tumor segmentation method based on Deep Neural Networks (DNNs). The proposed networks are tailored to glioblastomas (both low and high grade) pictured in MR images. By their very nature, these tumors can appear anywhere in the brain and have almost any kind of shape, size, and contrast. These reasons motivate our exploration of a machine learning solution that exploits a flexible, high capacity DNN while being extremely efficient. Here, we give a description of different model choices that we’ve found to be necessary for obtaining competitive performance. We explore in particular different architectures based on Convolutional Neural Networks (CNN), i.e. DNNs specifically adapted to image data.
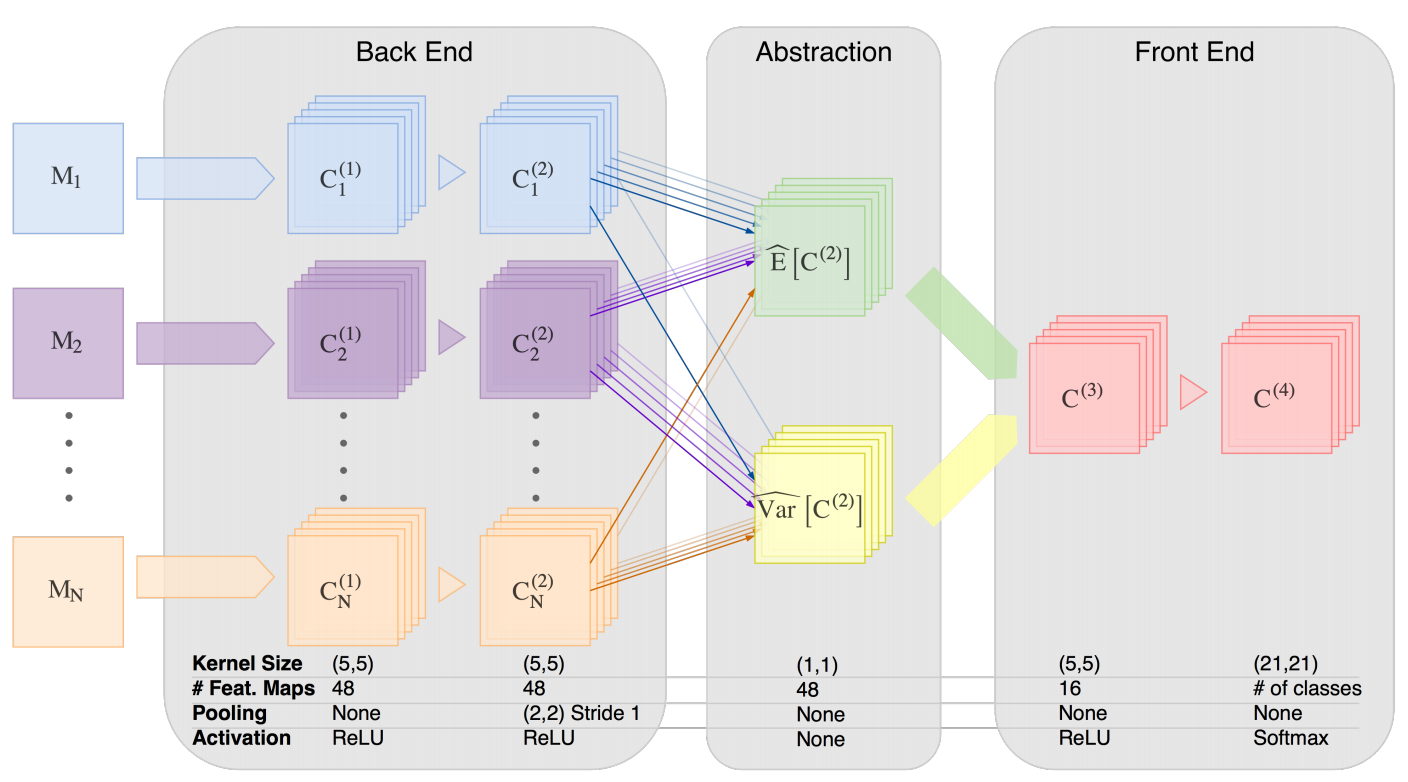
Hemis: Hetero-modal image segmentation
MICCAI 2016
We introduce a deep learning image segmentation framework that is extremely robust to missing imaging modalities. Instead of attempting to impute or synthesize missing data, the proposed approach learns, for each modality, an embedding of the input image into a single latent vector space for which arithmetic operations (such as taking the mean) are well defined. Points in that space, which are averaged over modalities available at inference time, can then be further processed to yield the desired segmentation. As such, any combinatorial subset of available modalities can be provided as input, without having to learn a combinatorial number of imputation models. Evaluated on two neurological MRI datasets (brain tumors and MS lesions), the approach yields state-of-the-art segmentation results when provided with all modalities; moreover, its performance degrades remarkably gracefully when modalities are removed, significantly more so than alternative mean-filling or other synthesis approaches.
Efficient interactive brain tumor segmentation as within-brain kNN classification
ICPR 2014
We consider the problem of brain tumor segmentation from magnetic resonance (MR) images. This task is most frequently tackled using machine learning methods that generalize across brains, by learning from training brain images in order to generalize to novel test brains. However this approach faces many obstacles that threaten its performance, such as the ability to properly perform multi-brain registration or brain-atlas alignment, or to extract appropriate high-dimensional features that support good generalization. These operations are both nontrivial and time-consuming, limiting the practicality of these approaches in a clinical context. In this paper, we propose to side step these issues by approaching the problem as one of within brain generalization. Specifically, we propose a semi-automatic method that segments a given brain by training and generalizing within that brain only, based on some minimum user interaction. We investigate how k nearest neighbors (kNN), arguably the simplest machine learning method available, combined with the simplest feature vector possible (raw MR signal + (x,y,z) position) can be combined into a method that is both simple, accurate and fast. Results obtained on the online BRATS dataset reveal that our method is fast and second best in terms of the complete and core test set tumor segmentation.
Invited Talks
Applicaitons of AI in Medical Imaging
Amirkabir University of Technology (December 2021)
In this talk I'll present some applications of AI in medical imaging and Ill go through technologies that enbable us deply AI in healthcare.
Challenges of applying deep learning in medical imaging
University of Dalhousie (July 2019)
Deep learning models have proved to be quite successful on benchmark datasets such as ImageNet. However, real-world applications do not follow the standard setting observed in benchmark datasets. This makes training deep learning models quite challenging in the wild. In this talk, I will highlight some major challenges facing applying machine learning techniques to medical imaging data and provide some solutions to address them. The challenges stem from various factors including but not limited to; a small amount of training data, missing data, dataset shift, weak labels, and ambiguous labels.
Emerging technologies in Healthcare
International Combined Orthopaedic Research Societies ICORS (June 2019)
Deep learning as an emerging technology in healthcare.
CAML: Conditional class-aware meta-learner
Montreal Institute of Learning Algorithms, MILA (June 2019)
Neural networks can learn to extract statistical properties from data, but they seldom make use of structured information from the label space to help representation learning. Although some label structure can implicitly be obtained when training on huge amounts of data, in a few-shot learning context where little data is available, making explicit use of the label structure can inform the model to reshape the representation space to reflect a global sense of class dependencies. We propose a meta-learning framework, Conditional class-Aware Meta-Learning (CAML), that conditionally transforms feature representations based on a metric space that is trained to capture inter-class dependencies. This enables a conditional modulation of the feature representations of the base-learner to impose regularities informed by the label space. Experiments show that the conditional transformation in CAML leads to more disentangled representations and achieves competitive results on the miniImageNet benchmark.